调研目的
神经网络的卷积+激活+池化经典3连现在已经进化成BN+卷积+激活+池化4连了,再多多数情况比如分类分割前期处理中,这样的操作已经足够。但如果我们希望提取一张图像的全局特征而不愿意使用全连接,那么有种新的网络结构可以考虑,这种结构叫self-attention block。
对我来说,我的目的是提取两张图片的特征然后做处理,我需要保持图1结构基本不变,在其中嵌入图2的整体语义,那么在这种情况下,我可以用经典4连来做图1的特征提取,而对于图2,self-attention将是不错的选择。
Geometric Attentional Block
来自Attacks on State-of-the-Art Face Recognition using Attentional Adversarial Attack Generative Network,做的是生成对抗样本的网络。在提取目标的特征过程中考虑到了要提取全局特征,所以有了下面的设计:
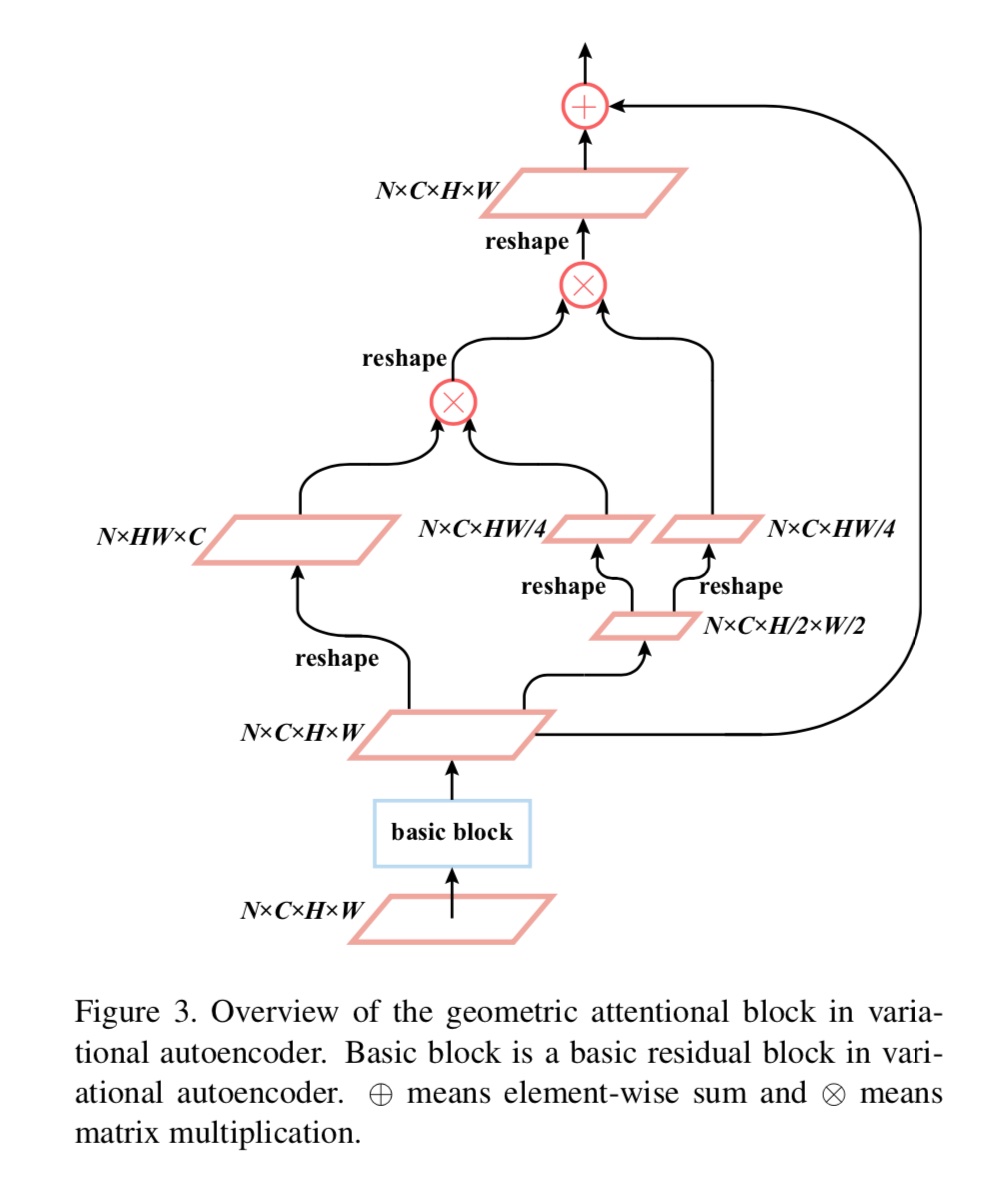
这个图已经相当清晰了,唯一的问题在于NxCxHxW是如何到NxCxH/2xW/2的,在下认为这就是个简单的降采样。
Denoise Block
这是谢慈航在FAIR的一篇paper,用滤波的方式消除对抗样本的影响。滤波block中需要attention block,结构如下:
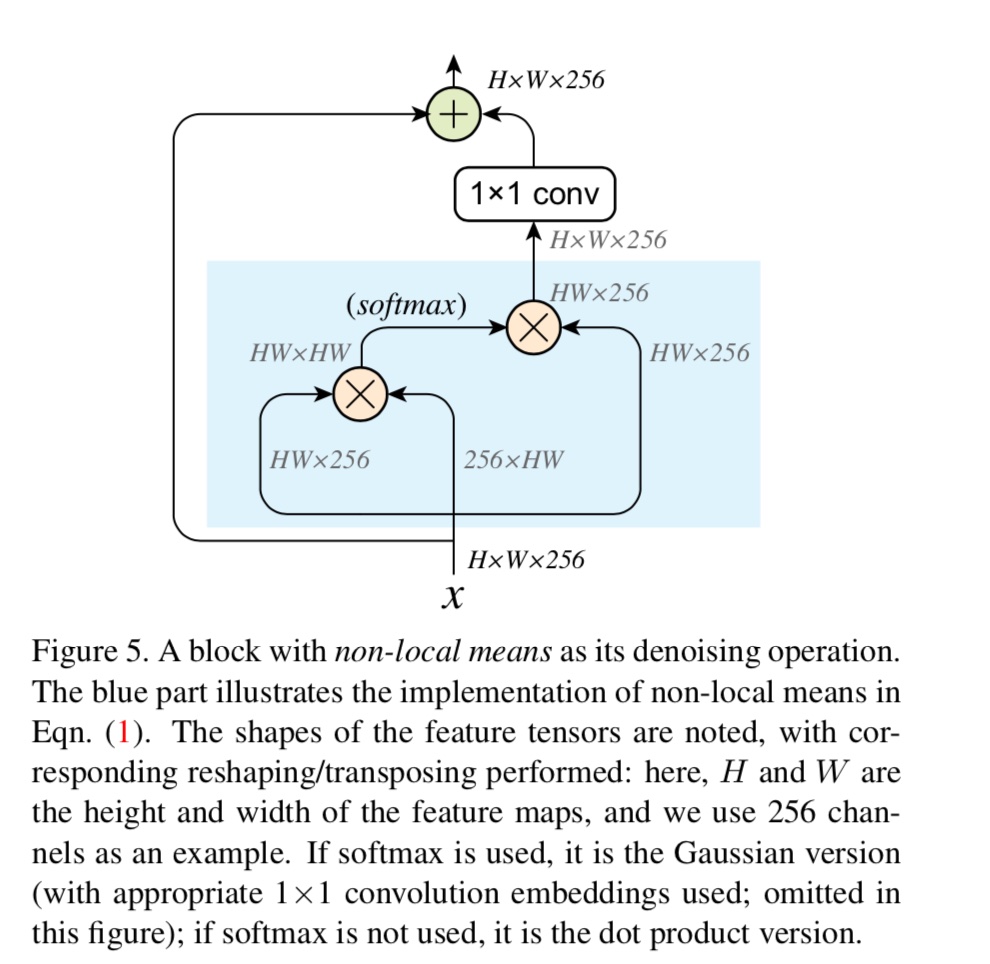
可以看到这个没有上面的复杂,但本质上差的不多,在论文里仔细看了下,所有这些想法的出处其实是17年一篇引用比较多的文章Non-Local Neural Networks。
Non-local Neural Networks
先上图:
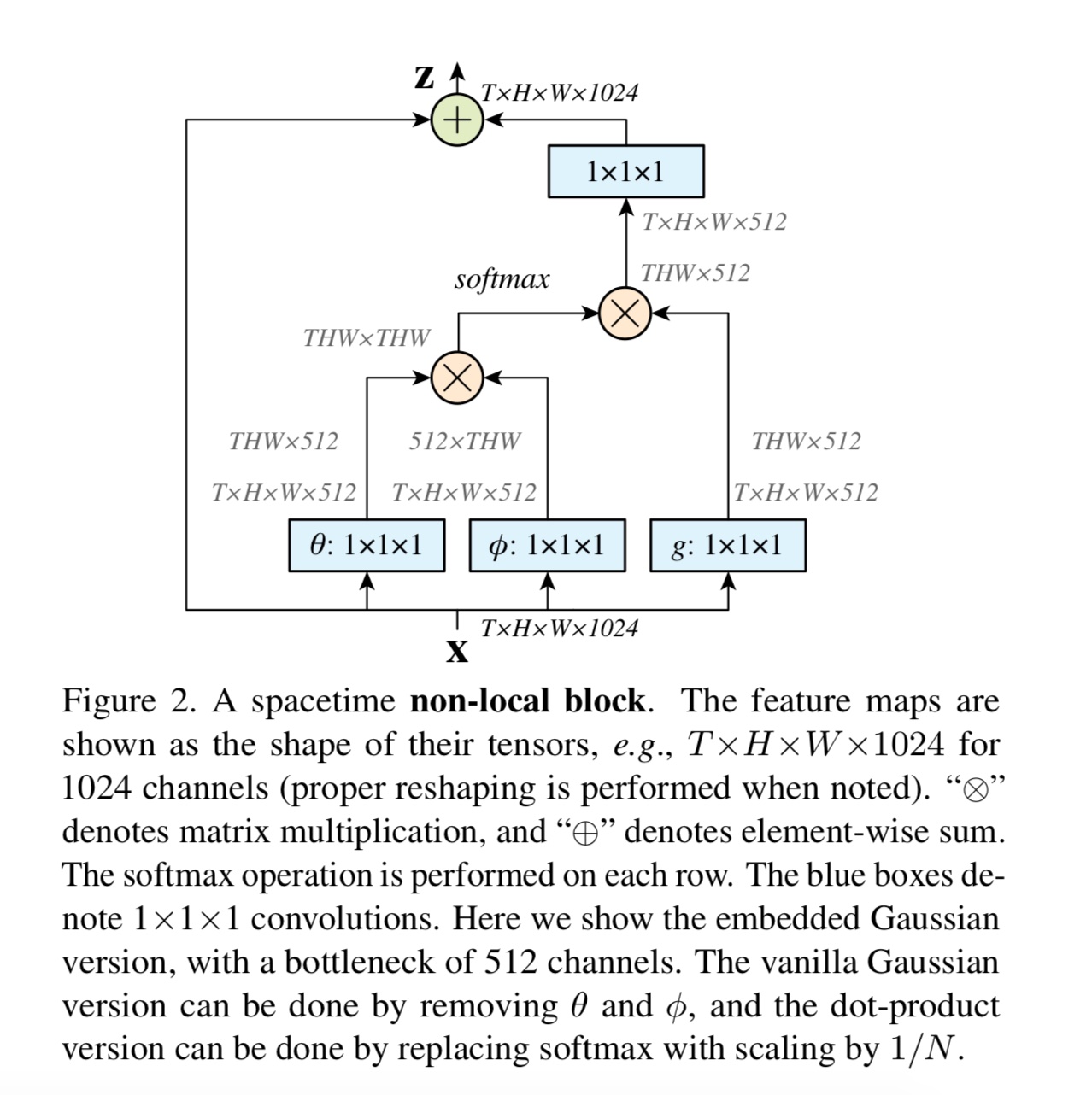
目的一样是为了让每个像素点都能够影响到特征空间中的所有点,而且有short-cut保证很深的网络也可以训练。目前我的个人理解是,self-attention其实就是non-local映射出来的特征层上每个值的大小作为attention的程度。