ResNet 细节
- Resblock在输入输出维度不一致时的处理:
- 多出的维度直接填充为0
- 对short cut做conv+batch norm
- 实际实现中会对channel较多的做down sample
- 发现了再更
Batch Normalization
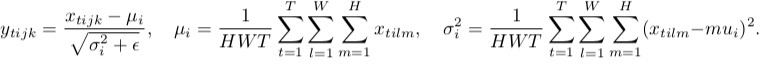
Instance Normalization
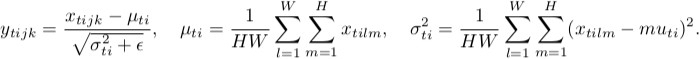
Batch Normalization is designed for gradient vanishing and covariance shift.
It makes a batch of input normalize to Gaussian distribution.
Instance Normalization is 1 sample independent across batch version of batch normalization.
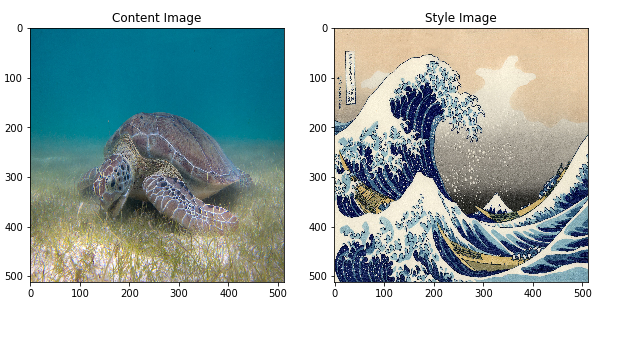

Given image_style, image_content.
Define distance functions: style_distance(img1, img2), content_distance(img1, img2)
content_distance: Euclidean distance between the intermediate representations of 2 images.
style_distance: A little bit complicated. see raw code:
1 | def gram_matrix(input_tensor): |
gram means correlation between different channels in intermediate layers.
New explanation:
我们从style transfer中使用的Gram matrix出发,试图解释为什么Gram matrix可以代表一个图片的style这个问题。这是我看完style transfer的paper后感觉最为迷惑的一点。一个偶然的机会,我们发现这个匹配两张图的Gram matrix,其实数学上严格等价于极小化这两张图deep activation的2nd poly kernel的MMD距离。其中,MMD距离是用来通过从两个分布中sample的样本来衡量两个分布之间的差异的一种度量。所以本质上,style transfer这个paper做的事情就是将生成图片的deep activation分布和style image的分布进行匹配。这其实可以认为是一个domain adaptation的问题。所以很自然我们可以使用类似于adaBN的想法去做这件事情。这后续有一系列的工作拓展了这个想法,包括adaIN[3]以及若干基于GAN去做style transfer的工作。
Li, Yanghao, Naiyan Wang, Jiaying Liu, and Xiaodi Hou. “Demystifying neural style transfer.” arXiv preprint arXiv:1701.01036 (2017)
即交叉熵。注意该值是不对称的,即 $D_{KL}(p,q) \neq D_{KL}(q,p)$
常用于检查两个经验分布是否相同,或者一个经验分布是否服从另一个已知的分布。该算法会返回两个结果: KS距离和p值。 其中KS距离表示KS检测中的绝对距离,该值越大二者差异越大,但由于样本个数等未归一化的影响因素,只看KS值是不准确的。于是有归一化后的用于显著性检测的p值,该值越大,二者越相关。通常的判据即KS值小且p值大,二者相关。
即在一个函数族中,选择函数,计算两个经验分布所有值输入函数所得结果的均值之差,最大的差值就是我们想要的距离。为了使距离合理,函数族必须满足:
已被证明函数族满足RHKS(Reproductive Hilbert Kernel Space,再生希尔伯特核空间)上的单位球时可以满足上两条性质。
马氏距离衡量两个样本之间的距离,同时还包含欧式距离所没有的特点,比如对于一个各位之间有关系的多维向量 $x = (x_1, x_2, …, x_p)^T$,其协方差矩阵为$\Sigma$,均值为$\mu$,则有其马氏距离为: $D_M(x) = \sqrt{(x-\mu)^T\Sigma^{-1}(x-\mu)}$
由于考虑了协方差矩阵,该距离比欧式距离更能反映出样本不同位之间的相关信息。